A few tweets this afternoon got me thinking about how I could “expose” all those url shorteners, to see the actual URL location before I click on the link. I see the added value on it for services like Twitter where you have a limited amount of characters available, but I mostly see the danger of clicking on links that redirect you to an unknown place. Not to mention you’re placing your “availability” of your link into the hands of a 3rd party. If their service goes down, your link no longer works.
But it’s mostly the first part I’m trying to “fix”: seeing where a bit.ly link would take you, without you clicking on it. This way, you can see evil links, even when disguised via URL shortening services.
The firefox extension#
I had never done it, but making a firefox extension sounded like a pretty cool challenge. Turns out 90% of the extension exists of pure JavaScript, the other 10% are XML files you use to create menus and interactions with the user. I know JavaScript, so that shouldn’t be a problem. And since I’m a sysadmin, I don’t need GUI’s. ;)
The set-up: spotting 301 and 302 redirects#
I had the idea this was going to be terribly easy in JavaScript. Since all I had to do was check if a URL had a 301 or 302 redirect in it, I thought I would use the XMLHttpRequest() method in JavaScript to make a call for a specific URL, and match any HTTP status code.
That turned out to be more tricky than anticipated, because the current implementation of XMLHttpRequest() simply follows 301 and 302 redirects to its destination , and returns you the actual page. There’s no way to disable it, a future version would have a parameter you can add to disallow automatic redirection. Which left me no choice at the moment to do the workaround in another (ugly) way.
Querying URLs via a custom PHP script#
Since XMLHttpRequest() was not an option, I’ve not made it so any URL that is being checked will be sent to a server of mine, which would do the HTTP Header checks and return an XML value my Firefox Extension can parse.
This does imply that any URL that is being checked (for now: any URL with less than 24 characters, protocol included) will be sent to my server. I’m in no way logging this, but I understand the security implications in this. To circumvent this, you can host your own version of the PHP files (see Github ).
The quirks#
For me, this was a test for making Firefox Extensions and fiddling around with them. So far, it worked.
The extension still has some quirks though. Since I use an OnPageLoad event, I can not fetch any content being loaded by ajax calls (yet). Unfortunately, that also includes services like Twitter, Facebook, Hootsuite, … The services that I had actually intended this extension for in the first place. I’ll look into fixing that, some day.
Redirecting redirects does not yet work. If you shorten an already shortened URL, you’ll only see the “next” shortened URL in the information bar. I still need to add some recursion to follow the location, if that as well is a 301 or 302 redirect.
How does it look?#
The very basic implementation now looks like this.

URL Shortener Revealer
The links in the top left corner are “test” links, where the last of the 4 is a custom URL shortener from bit.ly. When you mouseover that, you’ll see the original link in the statusbar (where it always is) and a small popup in the left bottom corner with the actual location, as well as the type of redirect (301 or 302, usually).
The workflow#
Here’s a small diagram of the steps involved in getting to the result. If it’s not clear, best just view the actual source of the application logic .
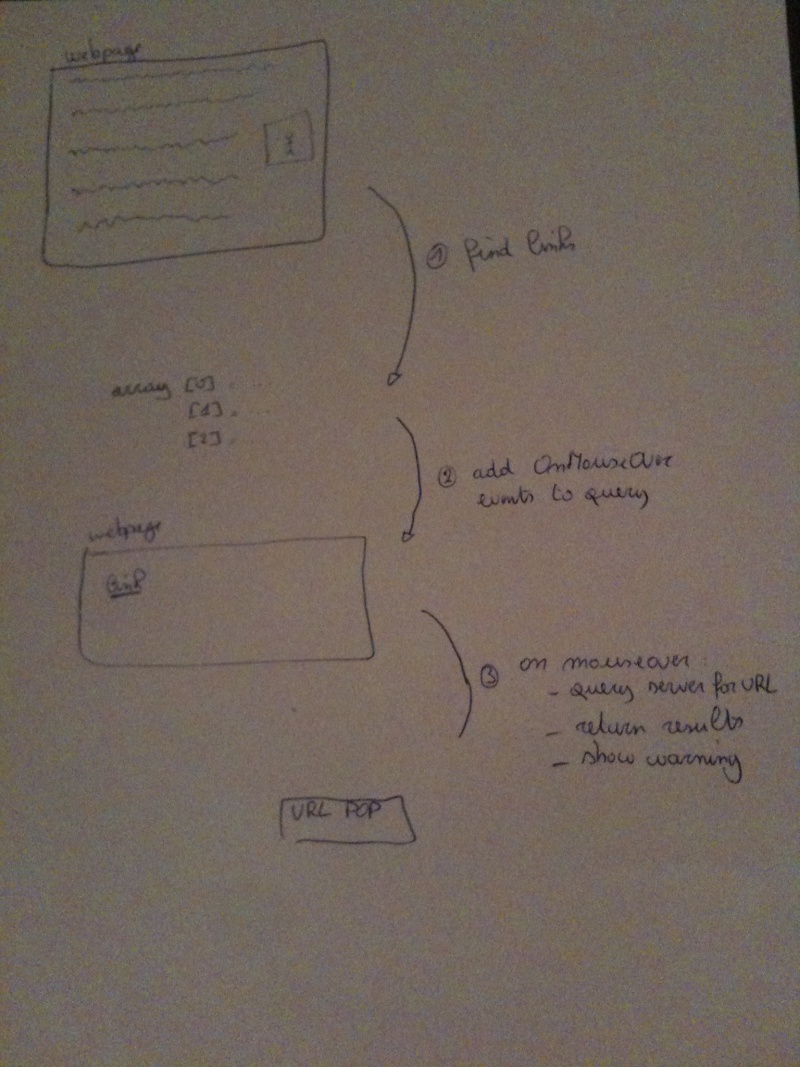
URL Shortener Revealer Logic
Want to try it?#
If you want to give it a go, the source code is entirely on Github . That includes the PHP file to host it yourself to be more “secure” about who you’re sending your links out to. The interesting files are the “ff-overlay.js ”, which holds the javascript code to add event handlers and parse the links, and the “index.php ” file which receives a URL as parameter and outputs the HTTP status code and new location. If you want to use “my” hosted solution (I don’t log anything, so feel free to), you can download the installer: [Shortlink Revealer.xpi][7].
Again, it’s a proof of concept, with a lot of flaws at the moment. I haven’t even checked yet if these kind of extensions already existed, I just wanted to try it myself. If you have any feedback, please share (here or at Github )!
*edit* I’ve been notified by [@pappie][8] that there’s a “[Long URL Please][9]” plugin that does similar work, by sending URLs to their server to parse them. This proves my point that it’s impossible with the current XMLHttpRequest() implementation, and that there’s always need to send it to a system that can check it.
There’s also a public API available for this, to match short URLs to their original URL via [LongURL.org][10]. Since that’s now the biggest bottleneck, to route everything through my server, I’ll see if I can change it to use their open API. By version seems “better”, as I simply scan _every_ URL I get passed to see if any redirects occur, the LongURL service seems limited to only some hostnames (so if you have a custom bit.ly domain name, that probably won’t work).
[7]: http://shortlinkrevealer.mattiasgeniar.be/firefox-extension/Shortlink Revealer.xpi [8]: http://twitter.com/#!/pappie [9]: http://www.longurlplease.com/ [10]: http://www.longurl.org/