Since about a week I’m running my own Bitcoin Core full node, one that keeps a full copy of the blockchain with all transactions included.
Node Discovery#
When you first start up your node, the Bitcoin Core daemon bitcoind queries a set of DNS endpoints to do its first discovery of nodes. Once it connects to the first node, more peers will be exchanged & the node start connecting to those too. That’s how the network initially bootstraps.
There are about 8 DNS Seeds defined in src/chainparams.cpp
. Each node returns a handful of peer IPs to connect to. For instance, the node seed.bitcoin.sipa.be returns over 20 IPs.
$ dig seed.bitcoin.sipa.be | sort
seed.bitcoin.sipa.be. 3460 IN A 104.197.64.3
seed.bitcoin.sipa.be. 3460 IN A 107.191.62.217
seed.bitcoin.sipa.be. 3460 IN A 129.232.253.2
seed.bitcoin.sipa.be. 3460 IN A 13.238.61.97
seed.bitcoin.sipa.be. 3460 IN A 178.218.118.81
seed.bitcoin.sipa.be. 3460 IN A 18.136.117.109
seed.bitcoin.sipa.be. 3460 IN A 192.206.202.6
seed.bitcoin.sipa.be. 3460 IN A 194.14.246.85
seed.bitcoin.sipa.be. 3460 IN A 195.135.194.3
seed.bitcoin.sipa.be. 3460 IN A 211.110.140.47
seed.bitcoin.sipa.be. 3460 IN A 46.19.34.236
seed.bitcoin.sipa.be. 3460 IN A 47.92.98.119
seed.bitcoin.sipa.be. 3460 IN A 52.47.88.66
seed.bitcoin.sipa.be. 3460 IN A 52.60.222.172
seed.bitcoin.sipa.be. 3460 IN A 52.67.65.129
seed.bitcoin.sipa.be. 3460 IN A 63.32.216.190
seed.bitcoin.sipa.be. 3460 IN A 71.60.79.214
seed.bitcoin.sipa.be. 3460 IN A 73.188.124.183
seed.bitcoin.sipa.be. 3460 IN A 81.206.193.115
seed.bitcoin.sipa.be. 3460 IN A 83.49.154.118
seed.bitcoin.sipa.be. 3460 IN A 84.254.90.125
seed.bitcoin.sipa.be. 3460 IN A 85.227.137.129
seed.bitcoin.sipa.be. 3460 IN A 88.198.201.125
seed.bitcoin.sipa.be. 3460 IN A 92.53.89.123
seed.bitcoin.sipa.be. 3460 IN A 95.211.109.194
Once a connection to one node is made, that node will share some of its peers it knows about to you.
There’s no simple way to get all node IPs and map the entire network. Nodes will share some information about their peers, but by doing so selectively they hide critical information about the network design and still allow for all transactions to be fairly spread across all nodes.
Initial Block Download (IBD)#
With a few connections established, a new node will start to query for the blockchain state of its peers and start downloading the missing blocks.
At the time, the entire blockchain was 224GB in size.
$ du -hs .bitcoin/blocks/
224G .bitcoin/blocks/
Once started, your node will download that 224GB worth of blockchain data. It’s reasonably fast at it, too.
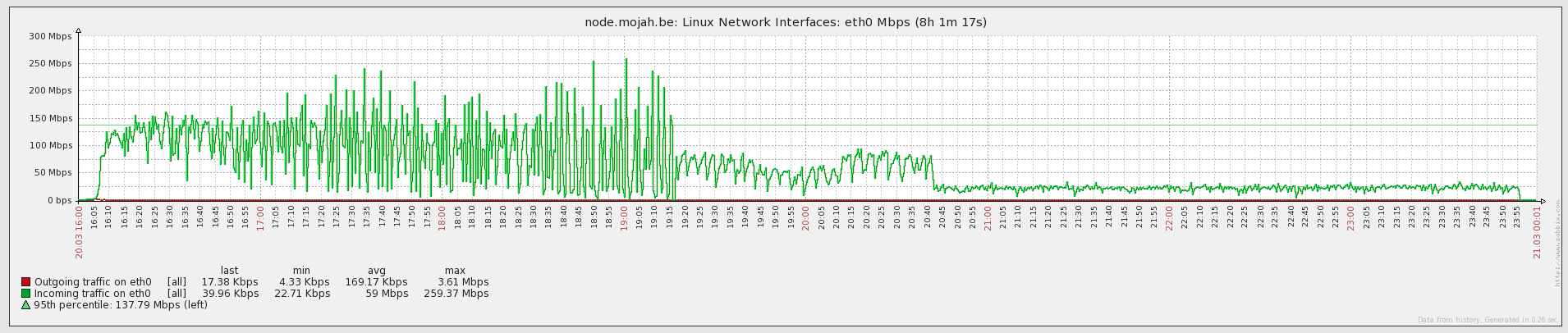
I was on a Gigabit connection at the time, the first 3/5th of the chain got downloaded at about 150Mbps, the rest slightly slower at 100Mbps and later at 25Mbps.
Notice how the bandwidth consumption changes over time and lowers? There’s a good reason for that too and it starts to become more obvious if we map out the CPU usage of the node at the same time.
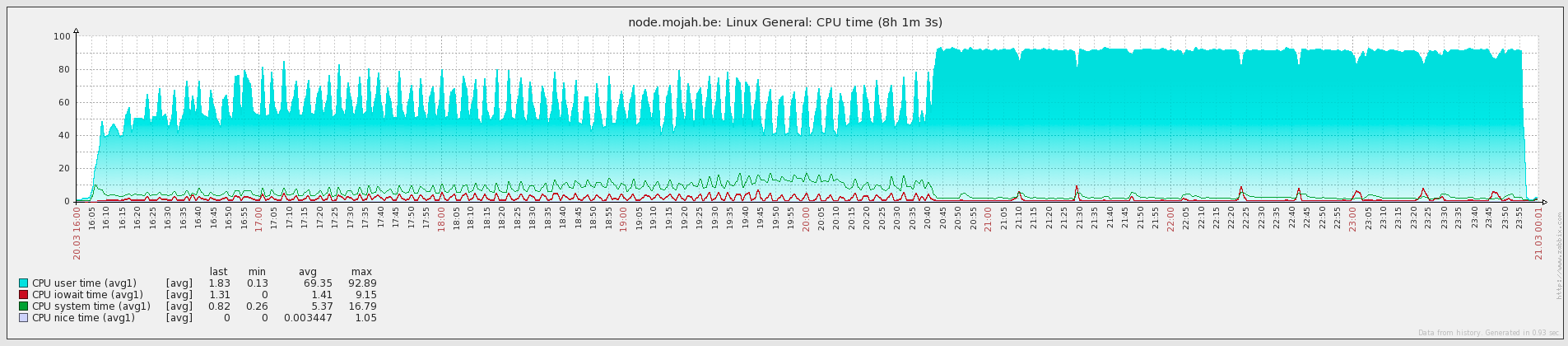
This wasn’t a one-off occurrence. I resynced the chain entirely and the effect is reproducible. More on that later.
Disk consumption#
Zooming in a bit, we can see the disk space is consumed gradually as the node syncs.

Also notice how, as the CPU usage starts to spike in the chart above, the disk consumption rate slows down.
It looks like at that point a more efficient algorithm was used, which is taxing the CPUs higher for block validation, but gives us a more efficient storage method on the disk.
Looking at the transaction timestamps in the logs, as soon as transactions around 2018-07-30 (July 30th, 2018) are processed, CPU spikes.
The IOPS appear to confirm this too, as the amount of I/O operations slows down as the CPU intensity increases, indicating writes and reads to disk are slower than usual.
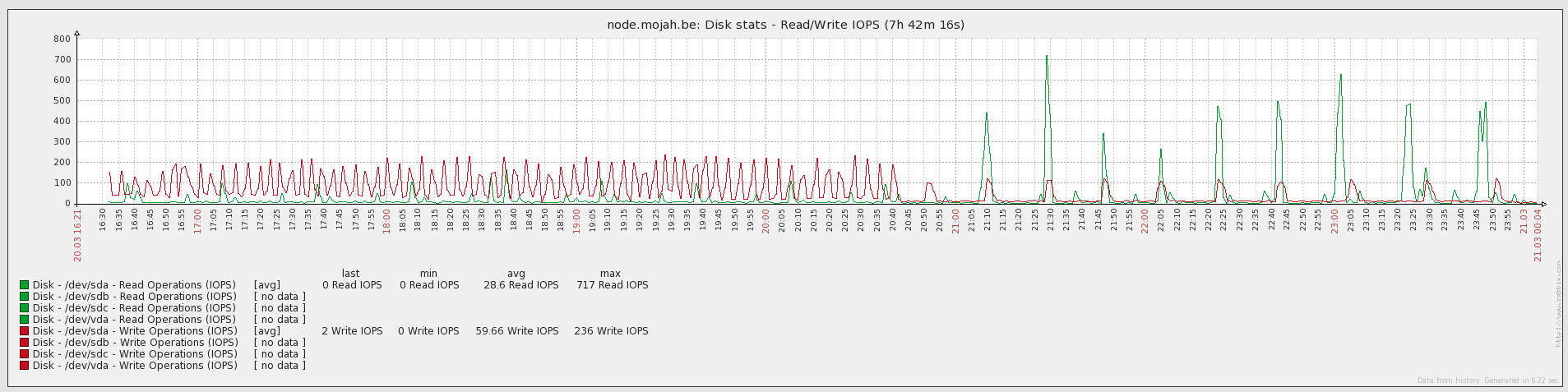
At first glance, this is a good thing. Syncing the chain becomes more CPU intense from that point forward, but as the block validation needs to happen only once when doing the initial block download, the disk space saved remains forever.
Thoughts on the block size#
There’s quite a lot of debate about the block size in Bitcoin: bigger blocks allow for more data to be saved and would allow for more complicated scripts or even smart contracts to exist on the chain.
Bigger blocks also mean more storage consumption. If the chain becomes too big, it becomes harder to run one on your own.
Because of this, I’m currently in the smaller blocks are better-camp. While diskspace is becoming cheaper & cheaper, back in 2019 a cloud server with more than 250GB disk space capacity quickly cost you around $50/month and started to add up over time.
We can’t change the current blockchain size (I think?), but we can prevent it from getting too large by thinking about what data to store on-chain vs. off-chain.
Setting up your own node#
Want to get your hands dirty with Bitcoin? One of the best ways to get started is running your own node and get some experience.
If you’re on CentOS, I dedicated a full article on setting up your own node: Run a Bitcoin Core full node on CentOS 7 .
If you don’t want to keep ~250GB of storage, you can limit the disk consumption by just keeping the newest blocks. For more details, see here: Limit the disk space consumed by Bitcoin Core nodes on Linux .