This technique isn’t new. In fact, it’s far from it. Around 2013, everyone seemed to be using this (or some variant of it) to deploy simple projects. But since then, it seems to have quiet down a bit. That’s a shame, because it’s super easy to use.
Here’s how it works.
A git-push-to-deploy scenario#
Imagine being able to do just the following to push a change to production.
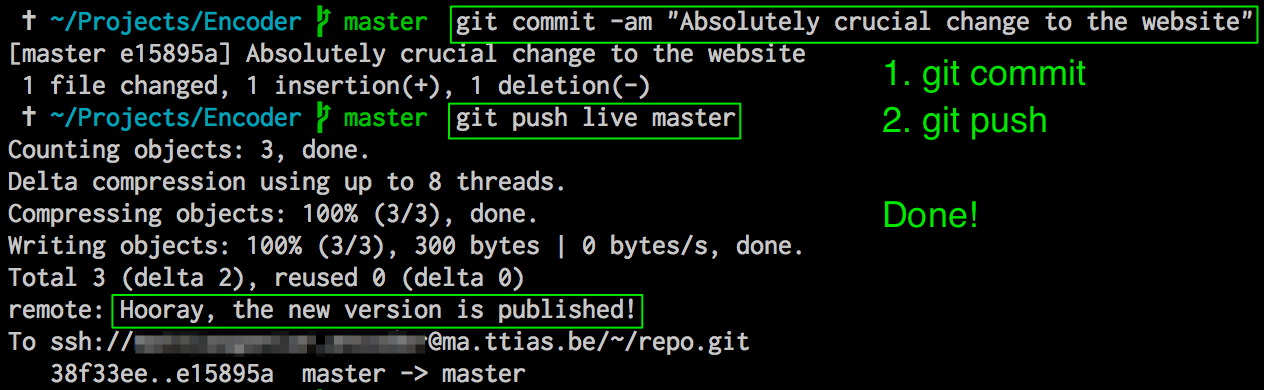
This boils down to just 2 commands to push your change to production (or any release cycle, really):
$ git commit -am "Commit this awesome change"
$ git push live master
This would be unthinkable in large projects (no code review, no approval process, …), but for simple projects this is absolutely dead easy to use.
Preparations on the server#
If you’re reading “server” and thinking “wait a minute, I don’t have a server”, this probably isn’t for you. You need a server (or at least: an SSH account, does not have to be root) in order for this to work. Shared hosting etc. probably won’t work, unless you’re given an SSH account which can execute git binaries.
Assuming you have the following directory structure for your site in your home directory:
$ ls -l
htdocs
logs
First, create a new directory that will contain your git repository data (the ‘raw’ data). I’ll name it repo.git in this example.
$ mkdir ~/repo.git
$ cd ~/repo.git
$ git init --bare
Your server is now ready to ‘host’ a git repository: that’s the magic behind git init --bare.
As a final touch, you need to add a post-receive hook to that repository. A post-receive hook is a simple bash-script (or any kind of executable, really) that gets called whenever this repository receives data from a git push.
We’ll use this to trigger an update of your live site whenever a new change is committed to this repository.
$ vim ~/repo.git/hooks/post-receive
Copy/paste the following content in there.
#!/bin/sh
git --work-tree=~/htdocs --git-dir=~/repo.git checkout -f
echo "Hooray, the new version is published!"
And make sure the file is executable.
$ chmod +x ~/repo.git/hooks/post-receive
When you first configure this, you’ll need to make a first git clone manually to your htdocs directory (if this directory already exists, either move it temporarily (as a back-up) or remove it altogether).
$ git clone ~/repo.git ~/htdocs
Now you’re all set to start receiving git pushes and auto-update your site.
Preparations on the client side#
On the client-side, you only need to add a new git remote location. This will refer to your newly created repository.
From within the root of your git repository (the top most directory), add your new git remote.
$ git remote add live ssh://your_username@your_hostname.tld/~/repo.git
This will add a new repository to your git configuration named live which points to ssh://your_username@your_hostname.tld/~/repo.git. The endpoint may look cryptic, but it’s just your SSH username @ server name or IP / path to your git repo.
If you were to list your git remotes locally, it would look like this (with different URLs, obviously).
$ git remote -v
live ssh://[email protected]/~/repo.git (fetch)
live ssh://[email protected]/~/repo.git (push)
origin [email protected]:mattiasgeniar/Encoder.git (fetch)
origin [email protected]:mattiasgeniar/Encoder.git (push)
For this example, I abused my string encoder/decoder tool, which you can also find on Github .
Now, whenever you do the following:
$ git commit -am "your commit message"
$ git push live master
… your server will receive the data from the git push and it will trigger its post-receive you configured above, making a checkout in your htdocs folder from the git repository.
Boom, your change is live.
Update: as was pointed out to me by @pjaspers , there’s a ruby gem called git-deploy that can help with most of the setup involved.