If you’re the owner or maintainer of a website, you know SEO matters. A lot. This guide is meant to be an accurate list of all technical aspects of search engine optimisation.
There’s a lot more to being “SEO friendly” than just the technical part. Content is, as always, still king. It doesn’t matter how technically OK your site is, if the content isn’t up to snuff, it won’t do you much good.
But the technical parts do matter, after all. This blogpost covers the following topics:
- Force a single domain
- Prefer HTTPs over HTTP
- Optimise for speed
- META tags: title & description
- Semantic page markup
- Eliminate duplicate content
- Clean URL structures
- A responsive layout
- Robots.txt
- Sitemap.xml
- Google’s Webmaster Tools
- Twitter Cards
- Facebook’s Open Graph
- HTML meta tags for indexing
- Crawl your site for 404’s
- Crawl your site for anything but HTTP 200’s
- Geolocation of your IP address
- Site maintenance: HTTP 503
As I’ve recently launched 2 side projects (MARC, the open source mailing list archiver and cron.weekly, my open source & linux newsletter ), I had to go through the usual SEO dance yet again.
But this time, I’m documenting my actions. Consider it a technical SEO checklist, whenever you launch a new site or project.
Without further ado, let’s get started.
Force a single domain: with or without WWW subdomain#
There are probably a couple of domain names that allow visitors to reach your website. The idea is to force a single one, set the correct HTTP headers for redirecting and force the single domain to be known.
If you’re running Apache, this is the easiest way to force all requests to a single domain. Add this to your .htaccess configuration.
RewriteEngine On
RewriteBase /
RewriteCond %{HTTP_HOST} !www.cronweekly.com$ [NC]
RewriteRule ^(.*)$ http://www.cronweekly.com/$1 [L,R=301]
This essential follows this logic:
- If the domain name (
%{HTTP_HOST}) does not matchwww.cronweekly.com - Then redirect to www.cronweekly.com with a Permanent Redirect (301)
Great, now any other domain that points to my site will be rewritten to www.cronweekly.com.
If you’re on Nginx, there are 2 ways to tackle this problem. A good and a better way. Here’s the easiest one to implement, as it only requires a simple change to your vhost configuration on the server.
server {
...
if ($http_host != 'www.cronweekly.com') {
rewrite ^(.*)$ http://www.cronweekly.com$1;
}
}
While it works, it isn’t the preferred way in Nginx. Here’s a better solution, but it requires a bit more configuration work.
server {
listen 80;
server_name cronweekly.com alternativedomain.com;
# Force rewrite for everything that reaches this vhost to www.cronweekly.com
return 301 http://www.cronweekly.com$uri;
}
server {
listen 80;
server_name www.cronweekly.com;
# The rest of your vhost logic goes here
}
The second example essentially creates 2 virtual hosts: one virtual host (the last one) that contains the configuration for your actual site. This should, ideally, only have one server_name component, the final domain name for your site.
The first server block has a set of server_name’s that are basically aliasses to the real site, but that shouldn’t be used. Any site that points to those domains will trigger the rewrite section and force the new domain to be used, which then enters the second vhost.
It’s a bit more configuration work, but it’s more efficient for Nginx.
Prefer HTTPs over HTTP#
This is up for debate, but one that I’ll stick to: make sure your website is available over HTTPs and force the HTTPs version everywhere.
Google prefers HTTPs over HTTP (even if it’s only by a 0.0001%), so if you have the possibility to activate HTTPs, go for it. Since the rise of Let’s Encrypt , several shared hosting providers even offer free SSL certificates to all their clients . That’s a free bargain you shouldn’t pass on.
Be warned though, implementing HTTPs isn’t without dangers : a good implementation gives you a nice green lock in the URL bar, but the slightest mistake (like mixed content, where you include HTTP resources in your HTTPS site ) can destroy that experience.
If you’re enabling HTTPs, make sure to redirect all HTTP connections to HTTPs. If you don’t, search engines could index 2 versions of your site and treat them differently: the HTTP and the HTTPs version.
In the examples above, make sure to replace http:// with https:// so the redirect goes to HTTPs straight away.
If you’re using Nginx as a reverse proxy in front of your Apache webservers (which is a common practice if you want to enable HTTP/2 on your sites
), you can use a configuration like this in your .htaccess.
RewriteEngine On
RewriteCond %{HTTPS} off
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI} [L,R=301]
In Nginx you can use a variation of the rewrite shown above. The virtual host that listens on port :80 redirects everything to the vhost on port :443 (HTTPs).
server {
listen 80;
server_name cronweekly.com www.cronweekly.com;
# Rewrite all to HTTPs
return 301 https://www.cronweekly.com$uri;
}
server {
listen 443 ssl;
server_name www.cronweekly.com;
# Your vhost logic goes here
}
When implemented properly, every variation of the domain name you type in your browser should lead you to the same domain name via HTTPs.
Page speed: optimising for responsiveness#
Google offers a very nice tool to test this: PageSpeed .
A faster website will get better rankings than a slow website. Even if it’s only a minor difference for search engines, it’s a massive difference for your visitors. A site taking more than 2-3 seconds to load will lose the interest of the visitor and could potentially cost you sales or leads.
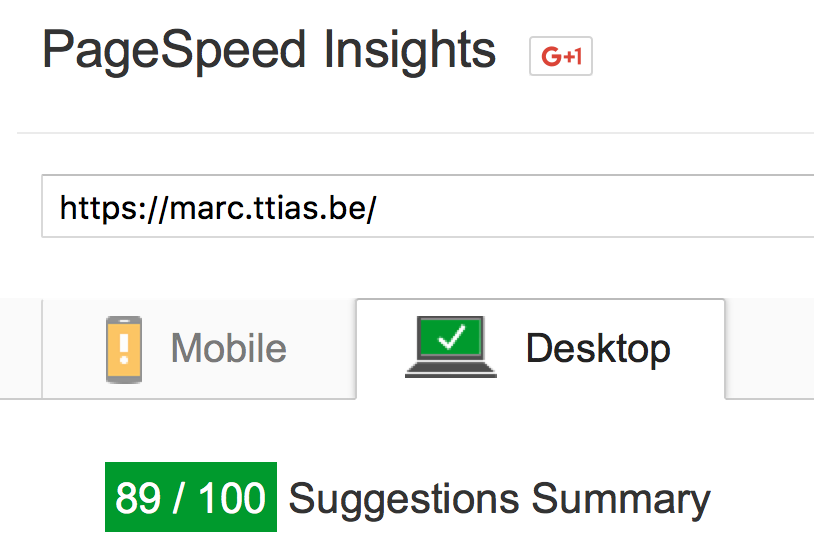
The result is a clear actionplan: which CSS or JavaScript to optimise, where to add cache headers, etc.
If you’re running an Apache, you can add the following to have your static content (like CSS, Javascript, images, …) be cached for up to 2 weeks. Add this to your .htaccess once again.
<filesMatch "\.(ico|pdf|flv|jpg|jpeg|png|gif|js|swf|css)$">
Header set Cache-Control "max-age=1209600, public"
</filesMatch>
If you’re confident every part of your site can be cached, you can remove the <filesMatch> block entirely and just set those headers for all content.
On Nginx, use something similar to this.
server {
..
location ~ \.(jpg|jpeg|png|gif|ico|css|js)$ {
expires 14d;
}
}
This sets an expiration header of 14 days for all content that matches that regex.
Set correct META tags: title & description#
A no-brainer, but something I did forget when I first created the mailing list archive . Setting the correct META tags for title and description is crucial for your site.
<HTML>
<title> Mailing List Archive - MARC</title>
<meta name="description" content="A public mailing list archive for open source projects.">
...
Every page should have a unique, clear title with a proper description. This is the entry ticket form the SERPs (Search Engine Result Pages). The title & description should be considered a teaser to lure the user into clicking your link.
Semantic page markup: h1, h2, h3, …#
Use the HTML elements to your advantage: h1 headers for your most important titles, h2 for the next level titles, h3 for the next ones, and so on. Google parses your content and uses those tags as its guideline.
Semantic markup goes a lot further than just h1 tags though. If you’re an event- or booking-site, you can add structured data to your markup that can be parsed and shown directly into Google’s search result pages.
Eliminate duplicate content (in some unexpected ways)#
Google doesn’t like it when you have the same content be shown on different pages. You’re penalised for it as it’s considered duplicate content and could be seen as a way to artificially increase the size of your site.
But duplicate content is something that’s very easy to get, even when you don’t promote it. Take for instance the following URLs:
http://yoursite.tld/page/?search=keyword&page=5&from=homepage
http://yoursite.tld/page/?page=5&search=keyword&from=homepage
http://yoursite.tld/search/keyword/?page=5
...
Those URLs could all be pointing to the same content: the position of the different URL variables, a clean version of the URL as rewritten by .htaccess files, …
For Google, those could look like 3 unique URLs with the same content. That’s not good.
These are a lot harder to fix and track down but it should be kept in the back of your mind when developing any new site. If there are multiple URLs to show the same content, either:
- Set the correct META tags to prevent indexing (
<meta name="robots" content="noindex,follow"/>) - Force a 301 permanent rewrite to the final URL
For websites that offer a search function this can happen quite a lot: different keywords showing the same results and thus the same content. Because of this, many people add the noindex,follow headers to search result pages to prevent those from being indexed.
Update: as correctly mentioned in the comments, another way to tackle this problem is by creating canonical URLs . This allows you to communicate one URL to search engines where multiple variants of that URL may exist.
Clean URLs#
If you remember the early 2000’s, you remember URLs like these:
site.tld/page.php?page_id=512
site.tld/profile.php?id=12
site.tld/forumpost.php?thread=66
...
These kind of URLs, where the database IDs are so clearly visible, are become more and more rare. Nowadays, you have URLs like these:
site.tld/9-ways-to-make-money-online
site.tld/profile/mattias-geniar
site.tld/forum/thread/how-do-i-undelete-a-file-in-linux
...
These URLs have a couple of things in common:
- The site’s information architecture is clearly visible: the URLs show the hierarchy in which content is organised.
- The URL contains keywords and usually gives away part of the content of the page, without opening the page yet (useful in search engine results to lure the user into clicking your link).
If you still have URLs like the first example, consider creating a clear hierarchy of all your pages and structure them like the 2nd example.
As for the whole “trailing slash or no trailing slash debate”: I don’t care about that. I don’t believe the trailing slash makes any difference from a technical SEO point of view, so pick a style that makes you happy.
Responsive layouts#
Responsive designs are given a higher score for mobile searchers than non-responsive layouts. If your current site isn’t made responsive yet, consider making it one of your priorities for the next redesign.
For the mailing list archive I simply relied on Twitter Bootstrap , the CSS framework which comes with responsiveness out of the box. One of the key technical aspects of a responsive layout is the presence of the following meta tag in the HEAD of the HTML.
<meta name="viewport" content="width=device-width, initial-scale=1.0">
Because of Twitter Bootstrap, it was a no-brainer to get a responsive layout. It didn’t take me any more work. As a non-webdeveloper, it did take me longer to get used to Bootstrap’s grid system and having to test the layout in multiple resolutions, but in the end – that effort pays of.
Robots.txt#
Search engines will look for a robots.txt file in the root of your website for instructions on how and if to crawl your site. The following file allows all indexing to occur, nothing is blocked.
User-agent: *
Disallow:
For a couple of live ones, see here: marc.ttias.be/robots.txt , google.com/robots.txt , nucleus.be/robots.txt , …
If you don’t want search engines to crawl portions of the site, add excludes like this:
User-agent: *
Disallow: /search
Allow: /search/about
Disallow: /sdch
Disallow: /groups
...
Be warned though: this is a suggestion to search engines. Google will honour it, but there’s no guarantee that tomorrows search engines will too.
Sitemap.xml#
A sitemap is a structured set of data (in XML) that lists all the pages of a site and when that particular page was last updated. It’s useful to get a comparison between all the pages you have, and the ones that have been indexed.
Here are a couple of ones as an example:
- marc.ttias.be/sitemap.xml.gz : a gzipped sitemap.xml
- cronweekly.com/sitemap_index.xml : an overview of multiple sitemap files
Most content management systems can generate these for you. If you’ve written your own code, there are probably community contributed modules that can help generate them.
If you’ve got a static website, where all files are already generated, you can use a python script to parse those files and generate a sitemap for you. This is what I used on the mailing list archive , since I had generated files on disk already.
This python script can do that for you .
$ /bin/python sitemap_gen.py --config=config.xml
The config comes included in the download, you probably only need to modify the following parts (leave the original version and just change out these parameters).
$ cat config.xml
<site
base_url="https://marc.ttias.be"
store_into="/path/to/htdocs/sitemap.xml.gz"
verbose="0"
>
<directory
path="/path/to/htdocs/"
url="https://marc.ttias.be"
default_file="index.php"
/>
A very simple config, you tell it which directory to index (~/htdocs/), the name of the site and where to output the sitemap file.
Done.
Google’s Search Console (formerly Webmaster Tools)#
Every site should be added to Google’s Search Console (this was called Webmaster Tools when I first wrote this post; Google renamed it in 2015).
This tool gives you insights in the crawl status of your site, which problems Google detected when crawling or parsing the site, …
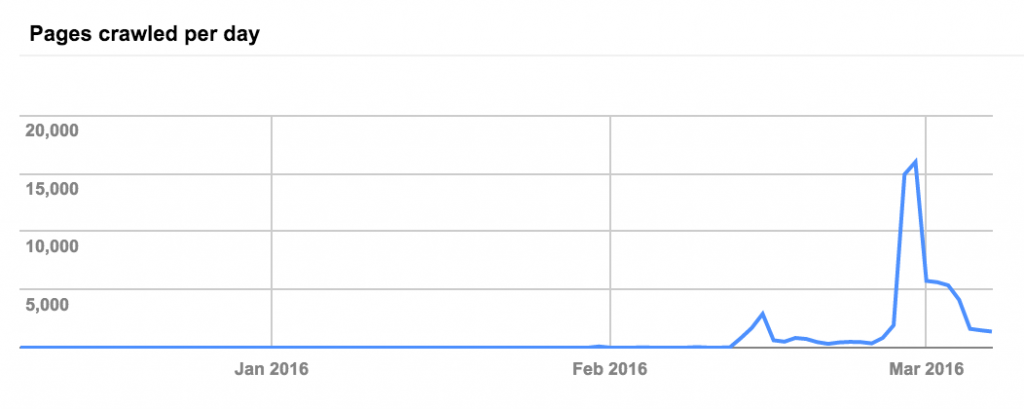
The Search Console also allows you to explicitly add your sitemap.xml and get feedback on which pages have been crawled and which have been added to Google’s Index.
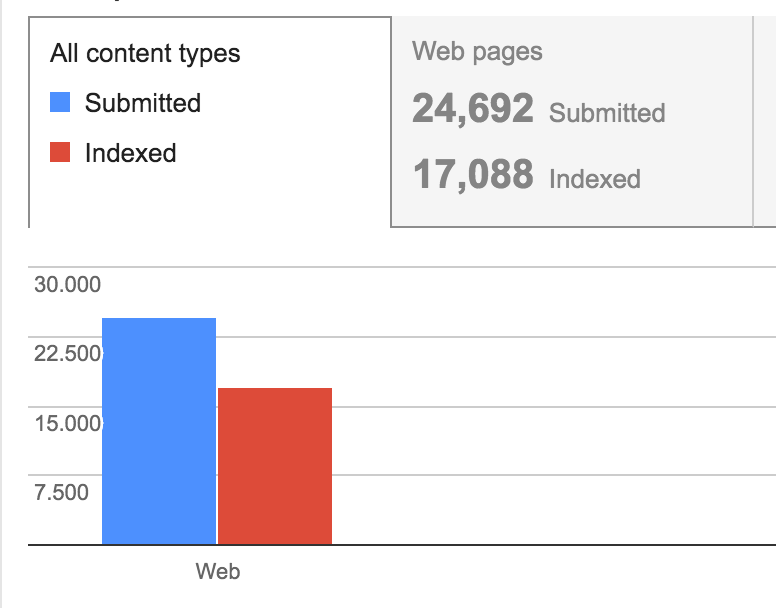
Adding the sitemap is no guarantee that Google will crawl and index all sites, but you can clearly see Google’s status and difference between what you submitted (the sitemap) and what Google crawled.
Twitter Cards#
“What does Twitter have to do with SEO?”
Well, more than you think. Having URLs that reached further trough social media increase the chances to be posted on multiple websites, thus increasing your organic reach and pagerank.
Implementing Twitter Cards doesn’t take a lot of effort, but the gains can be substantial.
You essentially add a set of additional header tags which Twitter can parse whenever a link is shared on the network. For MARC , it looks like this:
<meta name="twitter:card" content="summary" />
<meta name="twitter:title" content="[openssl-announce] OpenSSL Security Advisory" />
<meta name="twitter:description" content="Public mailing list archive for [openssl-announce] OpenSSL Security Advisory" />
<meta name="twitter:image" content="https://marc.ttias.be/assets/social_logo.png" />
<meta name="twitter:creator" content="@mattiasgeniar" />
<meta name="twitter:site" content="@mattiasgeniar" />
Now whenever a user shares a link to that site, Twitter parses it nicely and presents it in a more clean way. This should encourage more shares and further reach of your posts.
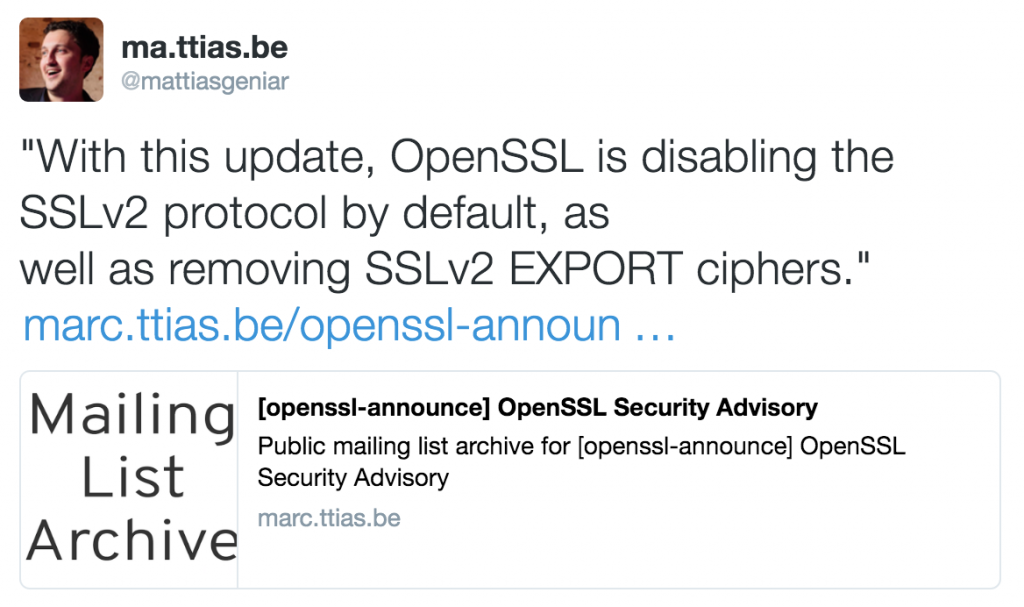
Which is better than just a post with a link, without additional content.
Facebook’s Open Graph#
For the same reason as Twitter Cards, you should implement Facebook’s Open Graph. Facebook also offers a URL debugger to help diagnose problems with those headers.
For MARC, they look like this.
<meta property="og:url" content="https://marc.ttias.be/openssl-announce/2016-03/msg00002.php" />
<meta property="og:type" content="article" />
<meta property="og:title" content="[openssl-announce] OpenSSL Security Advisory" />
<meta property="og:description" content="Public mailing list archive for [openssl-announce] OpenSSL Security Advisory." />
<meta property="og:site_name" content="Mailing List Archive (MARC)" />
<meta property="og:image" content="https://marc.ttias.be/assets/social_logo.png" />
In the debugger , they’re parsed like this.
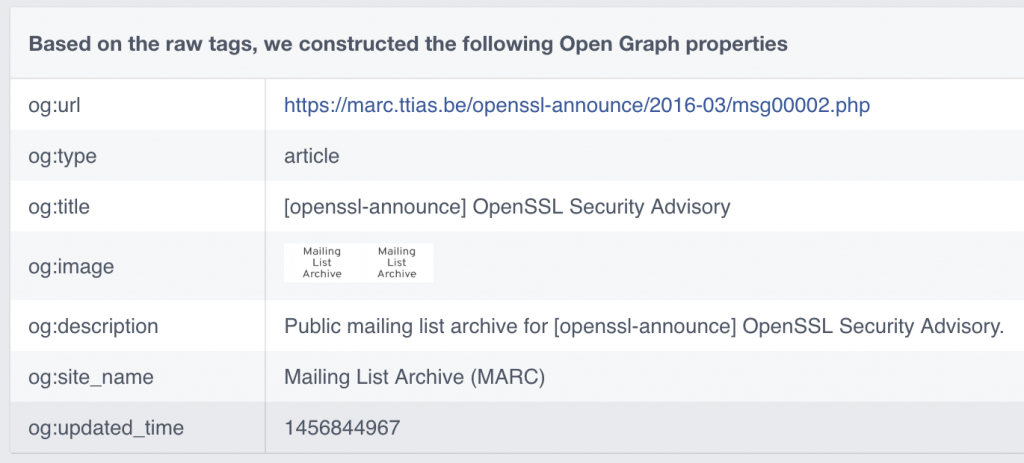
A better view in the timeline will increase the reach of any of your pages.
HTML meta tags for indexing#
Unless a particular page is blocked in the robots.txt, Google will assume the page can be indexed.
You can make this even more clear by adding HTML tags in the head that explicitly tell the search engine to index this page and follow all its pages it links to.
<meta name="robots" content="index, follow">
Alternatively, if this page shouldn’t be indexed (like on duplicate content pages mentioned above) you can prevent it with the noindex value.
<meta name="robots" content="noindex, follow">
There are some more variations possible you could read up on.
Crawl your site for 404’s#
Having dead pages or links is something to avoid, but if you have a site that’s been alive for a couple of years – chances are, you’ll have 404’s in your pages you have no idea about.
Here’s a very simple command line script to crawl your site and report any 404 found. Each of these should be checked or redirect to a new page (preferably by a 301 HTTP redirect, indicating a permanent redirect).
$ wget --spider -r -p http://www.cronweekly.com 2>&1 | grep -B 2 ' 404 '
--2016-03-09 22:08:14-- https://www.cronweekly.com/three-tiers-package-managers/
Reusing existing connection to www.cronweekly.com:443.
HTTP request sent, awaiting response... 404 Not Found
This told me, on my own site, that I linked to a page that wasn’t there anymore: it gave a 404 error.
Now I should probably look for where I linked to that page and fix the referer.
Crawl your site for anything but HTTP 200’s#
If you crawl your own site, ideally you should find only HTTP/200 responses. An HTTP/200 is an “OK, content is here” message.
Anything else could mean content is missing (404), broken (503) or redirect (301/302). But ideally, you don’t link to any of that content but directly to the final destination page.
So here’s a small crawler completely crawls your site and stores it in a file called ~/crawl_results.log.
$ wget --spider -r -o ~/crawl_results.log -p http://www.cronweekly.com 2>&1
The result is in the ~/crawl_results.log file:
$ cat ~/crawl_results.log
...
--2016-03-09 22:13:16-- https://www.cronweekly.com/
Reusing existing connection to www.cronweekly.com:443.
HTTP request sent, awaiting response... 200 OK
2016-03-09 22:13:16 (114 MB/s) - 'www.cronweekly.com/index.html' saved [17960]
You can now analyse the resulting log file for any HTTP status code that wasn’t expected.
Geolocation of your IP address#
If you have a site targeting Belgium, make sure to have the site hosted in Belgium.
The WHOIS data behind IP addresses can specify a location. For Google’s “local” results, the location is – in part – determined by the IP address that is hosting your site.
So if you went to Hetzner , a massive German hosting provider, because it was cheap, but your business is aiming at Belgian visitors, you’re much better of hosting your site at Nucleus, a local Belgian hosting provider . If you’re targeting Norway, host your site in Norway. etc.
If you’re targeting multiple regions, consider a couple of extra technical features:
- A CDN like CloudFlare, that helps you host your site across the globe by mirroring it
- Set up your own proxy in multiple languages, and redirect your .NL domains to a proxy in the Netherlands, a .BE domain to your proxy in Belgium, etc.
In short: be where your visitors are. It’ll give them lower latency and a faster experience, and Google will keep the location in mind when serving local results.
Site maintenance: HTTP 503 errors#
Whenever you have to take your site offline for a longer period due to maintenance, consider sending out HTTP 503 headers to all pages.
An HTTP 503 header means “Service Unavailable”. And that’s exactly what happens during maintenance.
Google won’t index a 503 and it’ll consider it as “temporarily not working”, so it can try again later.
You can even redirect your visitors to a page explaining the maintenance, while still serving the HTTP 503 header for all indexing bots. A rewrite rule like this triggers that behaviour.
RewriteEngine On
RewriteCond %{SCRIPT_FILENAME} !maintenance.html
RewriteRule ^.*$ /maintenance.html [R=503,L]
ErrorDocument 503 /maintenance.html
## Make sure no one caches this page
Header Set Cache-Control "max-age=0, no-store"
All traffic gets redirected to /maintenance.html while keeping a correct HTTP status code.
More technical TODO’s?#
If I’m missing more technical tips to improve your SEO, let me know – I’d love to learn more!