“Faking” your browser’s User Agent was a hot trick a couple of years ago. It allowed you to access websites that were only accessible to Internet Explorer, with Firefox – just by passing on another User Agent. After all, it’s the User Agent that actually tells the web server what your Browser is.
Over the years, more and more websites began implementing a user registration system, which prevent visitors from seeing site content until they registered at the website. This of course, posed some problems towards search engines – as they couldn’t see the content of the website either. So quite a few sites began creating a “User Agent Dependant Website”. If they noticed the User Agent was that of the Yahoo! or Google webcrawler, they would display to content – without the forced registration.
A lot of websites still use that trick, but have refined it by including a filter based on the IP address of the visitor. So you’d need GoogleBot’s User Agent, as well as a Google IP address to gain access without registering.
But even now, you can do cool things by changing your User Agent. This can easily be done using Firefox and the User Agent Switcher add-on. By default, it will allow you to switch between the default one (Firefox), Internet Explorer 7, Netscape 4.8 and Opera 9.25 .
Install the add-on, and add the GoogleBot user agent by defining the following values. (Tools > User Agent Switcher > Options > Options)
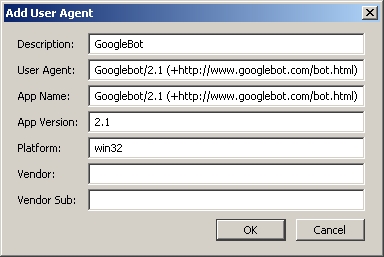
Now you can select it through the Tools > User Agent Switcher menu, and you can act as a GoogleBot when browsing websites.
A few things I’ve noticed right from the start, is that Google itself uses the User Agent to determine what content to display. Take the following screenshots for example, it’ll show you how Google.com looks like with a default (Firefox) User Agent (although the language is Dutch, it should be the same for any other language).

![]()
And this is what it looks like, when you browse it using a GoogleBot User Agent.
![]()
You’ll notice that the numbers of the pages, including the “Volgende” (= “Next” in English) text are slightly different. The header, which also displays the web history and notes tab, is shortened with GoogleBot’s User Agent.
Whenever you click on a link in the Google Search Results, and it brings you to a page that requires a login, it can usually be bypassed using the Googlebot User Agent, after all – Google was able to index that page, wasn’t it?
Here are some sites that actually show different content, based on the User Agent:
- GovernmentSecurity.org forum
- NYTimes.com (links to a specific article, for testing purposes)
- Experts-Exchange.com (not: expert sex change)
If you have any other sites that allow this trick, do share them! :-)
*Edit*: Turns out experts-exchange.com still works with this trick, you can use to browse the results without paying! You might have to do a hard refresh (ctrl + F5) in order to clear the cache, but it definately still works.