In this series, we are talking about Linux performance measurement, how to measure it right. Linux performance is a very broad topic, so we’ll focus on the four primary resources which are typically going to drive your system performance – obviously CPU, memory, disk storage, and network.
Other parts in this series include:
- Measuring Linux Performance: CPU
- Measuring Linux Performance: Disk
- Measuring Linux Performance: Memory
- Measuring Linux Performance: Network
In terms of network, we should be looking at three things: bandwidth, latency, and packet loss (also would be seen as errors).
You can think about the network from a global standpoint, it is actually quite hard to observe, and the local, which is between you and the switch.
Latency#
In terms of latency, for various reasons, the best way to measure the latency is at your application level.
It’s just a ping between two endpoints that may give you a good idea about the network latency and especially in case the network gets loaded. As for external measurements, we can do ping or mtr, which gives us more information about where packet loss potentially happens, and where latency originates.
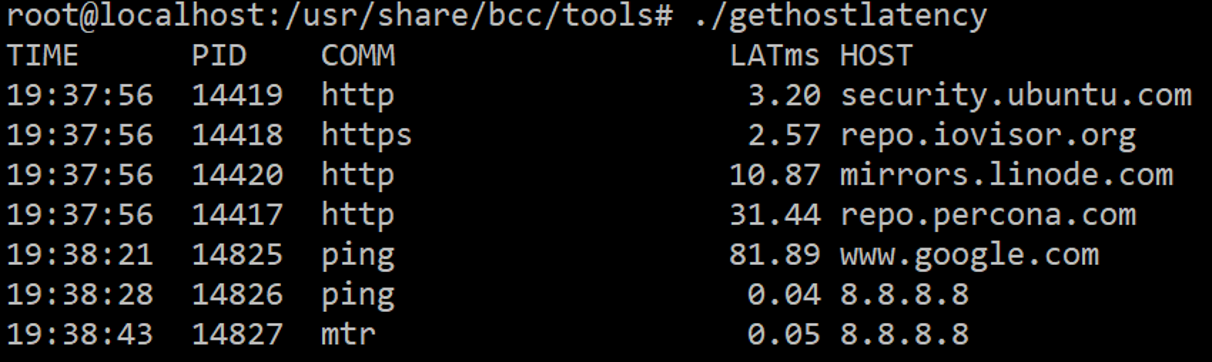
Another interesting piece about the network which I think often is unmeasured is a part of DNS lookup. You often say, “Hey, we do DNS and when we connect, the DNS is supposed to be magic slow, it seems to be cached”.
But in reality, it can’t be slow, especially for reverse DNS. We can use tools from the BCC collection, which gives us some good ideas.
Bandwidth#
For network bandwidth, you just need to make sure you know your limits, wherever there’s a network storage limit. Maybe something is placed as a VM over a cloud, and if you are going to saturate the network by 100%, you will see queuing happening.
That’s not good for your application, especially for some applications relying on sending a lot of small packets. It may be starving when you’re pushing some large packets through the network.
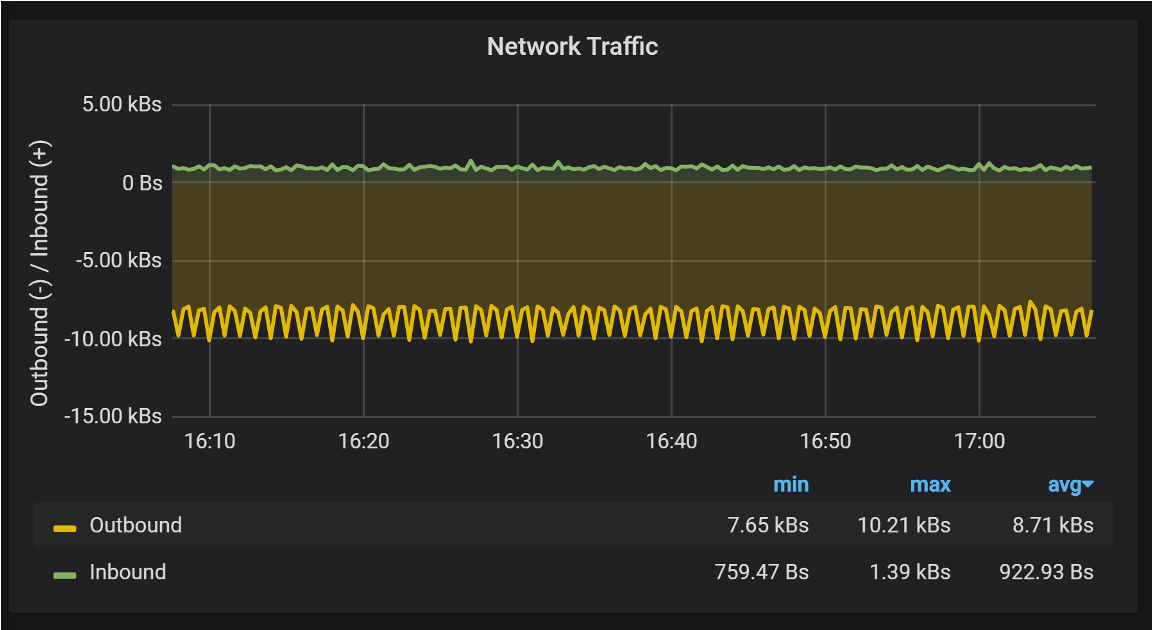
Most Networks are full-duplex. Performance can be limited by Switch/Cloud/Hypervisor. Graph from Percona Monitoring and Management (PMM).
Another thing from the local network standpoint is that you want to make sure there are no errors. Typically, there is none but even if there are a few, maybe you have a bad cable, bad drivers, bad network. You will need to fix it, or get it in a VM if it is in a cloud.
Packet Loss and Retransmits#
That is another important thing, as a lot of network performance problems between two endpoints happen because of packet loss and retransmits, but not because the speed of light is too slow.
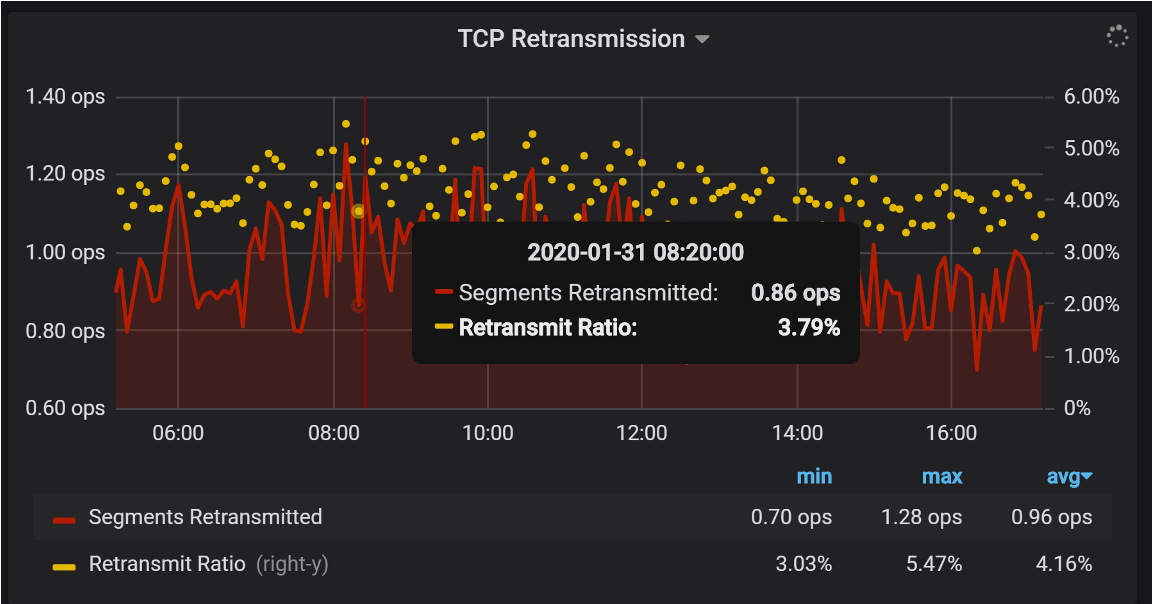
Performance killers on the network with good “ping” latency. Graph from Percona Monitoring and Management (PMM)
Especially, if you’re in relative proximity you can watch retransmits. Some will happen, but they shouldn’t be high. In this case, I feel the three percent retransmit rate is pretty high.